
ㅇTL
Hash 본문
Concept
*

• Hash : 많은 양의 데이터들을 그보다 작은 크기의 테이블로 대응시켜 저장할 수 있는 알고리즘
데이터를 특정 위치에 쌍으로 저장하는 것인듯!
해시란 데이터를 다루는 기법 중에 하나로 검색과 저장이 아주 빠르게 진행됩니다!
데이터를 검색할 때 사용할 key와 실제 데이터의 값이 (value가) 한 쌍으로 존재하고,
key값이 배열의 인덱스로 변환되기 때문에 검색과 저장의 평균적인 시간 복잡도가 O(1)에 수렴하게 됩니다.
hash function h(k)을 사용하여 key를 주소로 mapping해주어 빠르게 searching이 가능하도록 하는 방법이다. hashing은 key와 주소가 직접 연결된 구조가 아니라 hash function을 통한 key와 임의의 주소로 연결되는 구조이다.
원래 데이터 값이 정수로 변환되어서 인덱스로 활용되게 된다
- hash table : hash 기법을 이용해 데이터를 저장하는 자료구조
임의의 데이터를 hash값으로 대응. 데이터가 같으면 대응되는 hash값은 무조건 같고 데이터가 달라도 hash값은 같을 수 ㅇ
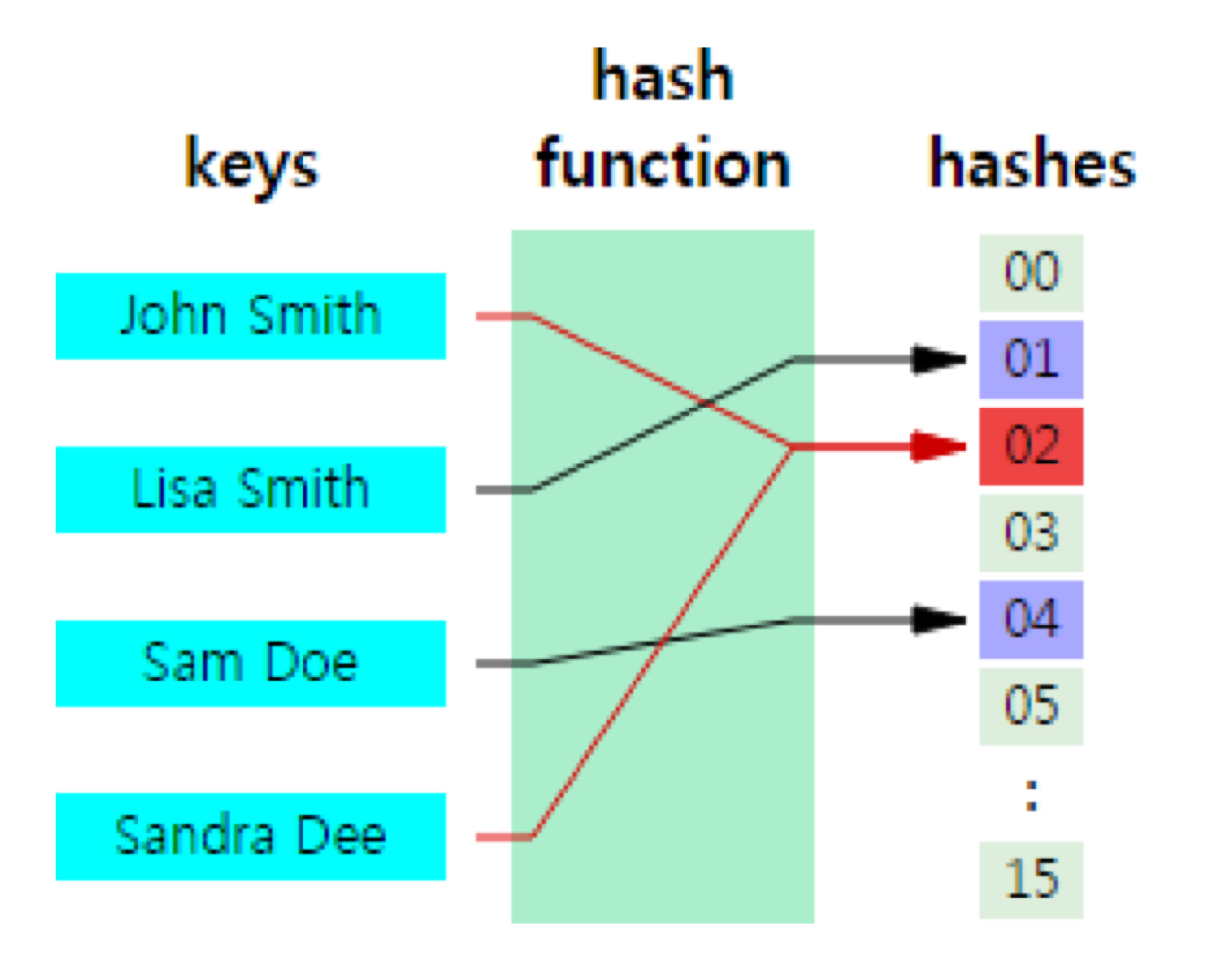
용어
- 키 : 입력 데이터
- hashing : 키값에 hash function을 적용하여 뭐여
- hash table : 키 값들이 해싱을 통해 나온 결과대로 저장해두는 자료구조
hash 구현에 필요한 자료구조
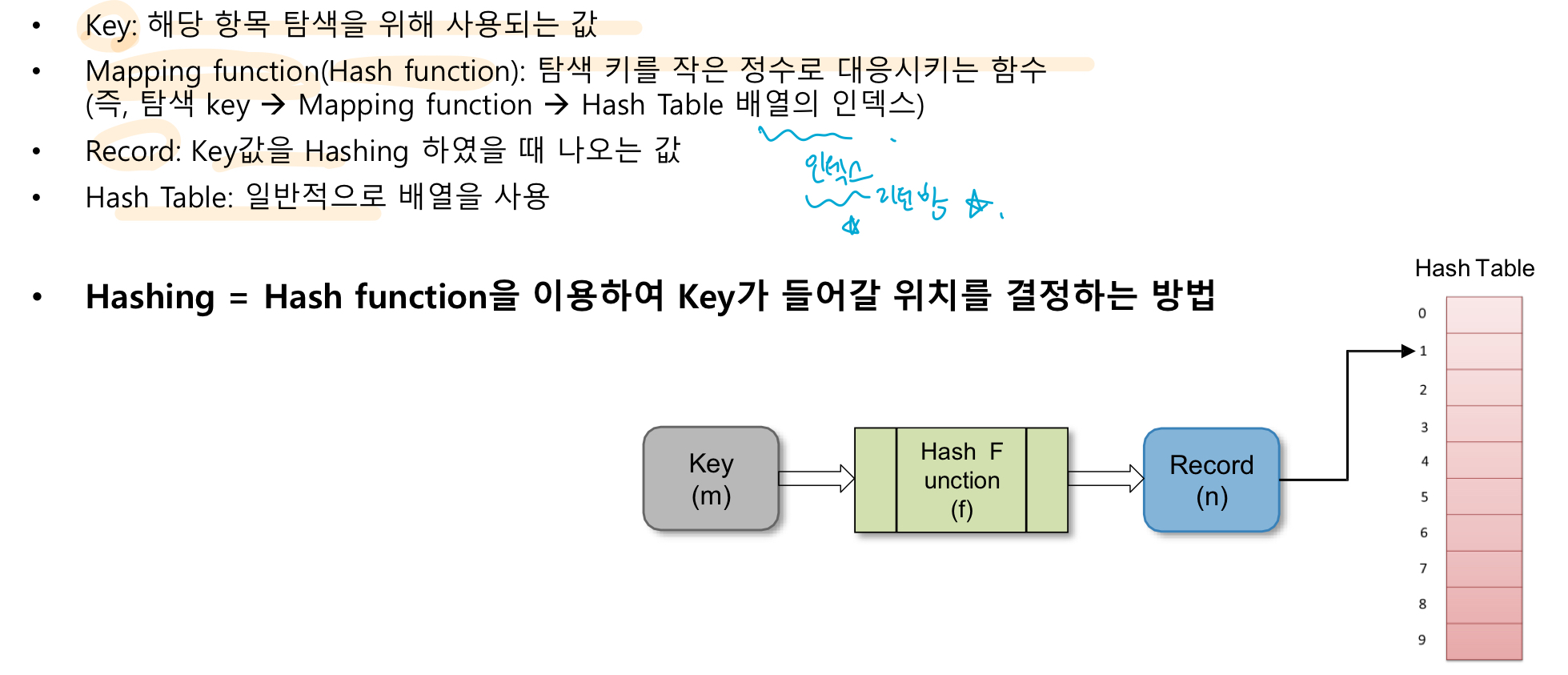
* Collition 발생 가능 !
(= 서로 다른 key값 갖는 항목들이 같은 hashing 결과값(해시 주소) 갖게 되는 현상. 서로 다른 키가 하나의 주소에 mapping 되는 것)
-> 두가지 방법으로 해당 항목을 hash table에 추가한다
1. Linear probing ; hash table의 다른 위치에 추가하는 방법 ; 해당 인덱스 차있으면 다음 인덱스 자리에 넣는방법
2. Chaining ; linked list를 이용하여 하나의 위치에 여러 항목 저장할 수 있도록 하는 것. 새로 들어온게 앞으로감
Extensible Hashing
앞에서 살펴본 hashing은 direct hashing으로 key에 hashfunction을 적용하여 직접 mapping하였다. 이 방법은 삽입이나 삭제를 많이 하는 dynamic file에서는 모든 파일을 재구조화해야하므로 낮은 성능을 보인다. 따라서 새로운 hashing 방법이 필요하다.
문자열의 prefix에 따라서 버킷을 가리키는 pointer를 directory에 저장하는 방법이다. prefix에 따라 다른 버킷에 저장
버킷이 full->overflow! -> 디렉토리의 크기를 두배로 증가 ...?
'2-1 > 자료구조 (c)' 카테고리의 다른 글
| Red black tree & B-tree (0) | 2022.06.06 |
|---|---|
| Sorting (0) | 2022.06.02 |
| AVL tree (0) | 2022.05.30 |
| Heap (0) | 2022.05.30 |
| Stack, queue (0) | 2022.04.17 |


