[ network application ]
= 컴퓨터 네트워크가 존재하는 이유. 웹, 유튜브, 롤, 등등등 .. text message, skype, search
0. 개발시
- 각 다른 end 시스템에서 동작하며 네트워크를 통해 서로 통신하는 프로그램을 만든다 (그런 소프트웨어를 만드는 것. 자바, 파이썬..등으로)
- 라우터나 링크 계층 스위치 같이 네트워크 코어 장비에서 실행되는 소프트웨어 작성 필요 없음! (네트워크 코어 장치는 유저 어플리케이션 돌리지 않음. 걍 하위 계층 친구들 꺼 신경쓸 필요 없음)
1. 구조
( 애플리케이션의 구조와 네트워크 구조는 다름! 애플리케이션을 위한 통신은 end system간의 application layer에서 발생함 )
1. client-server architecture
서버 : 항상 켜져있는 호스트, 고정 IP라는 알려진 주소를 가짐, 클라이언트라는 다른 호스트들에게 요청을 받음
클라이언트 : 서로 직접적으로 통신 x (클라이언트끼리 x) , 항상 켜져 있지 않고, 서버에 서비스를 요청하는 호스트. 서버와 통신
* 때때로 하나의 서버 호스트가 모든 클라이언트에게서 온 요청 처리하는 것 불가 -> 구글 네이버 같은 웹 사이트들은 많은 수의 서버를 갖춘 데이터 센터를 운영함!(10만개정도의 서버 갖추고잇슴 ㄷ)
2. P2P archi (peer to peer)
: 특정 서버를 통하지 않고, 호스트 쌍이 서로 직접 통신. 인터넷에 연결된 다수의 개별 사용자들이 중개 기관을 거치지 않고 직접 데이터를 주고받는 것을 말한다. 각 개인 = peer
관리 어렵 complex management
ex) 스카이프
특성- 자가 확장성 (self-scalability) : 높은 확장성을 가진다.
2. 프로세스 간 통신
: end 시스템에서 실제로 실행되는 프로그램 = 프로세스
(프로그램은 exe실행파일, 프로세스는 직접 작업하는 주체. 한 프로그램안에 여러 프로세스가 존재한다)
-> 운영체제 상에서 실행 중인 프로세스 간에 정보를 주고받는 것을 말함
그냥 네트워크 공간 상에서 데이터를주고 받는 다는 것은, 호스트의 프로세스 간에 데이터가 오고감을 의미한다!!
ㄷㅏ른 호스트(다른 종단 시스템) 에서 프로세스는 컴퓨터 네트워크를 통한 메세지 교환을 통신함
통신하는 프로세스 -> 클라이언트 프로세스(서비스 받는 프로세스), 서버 프로세스(서비스 제공 프로세스)
클라이언트 프로세스: 통신 시작하는 프로세스 (서비스 제공받을라고)
서버 프로세스: 접속 기다리는 프로세스
(P2P -> 한 프로세스가 서버,클라이언트 프로세스 둘다가 될 수 있다)
소켓
: application layer 와 transport layer 간의 인터페이스. ( 어플리케이션과 네트워크 사이의 API)
- >프로세스는 소켓을 통해 메세지를 보내고 받는다
컴퓨터 세계관에서는 프로세스가 데이터를 보내고 싶다고 해서 막 보낼 수 있는 게 아니고, 그들만의 법칙이 있는데, 바로 보내는 쪽도 받는 쪽도 소켓을 열어야 한다는 점이다. 보내는 쪽이 소켓이라는 창구를 열고 소켓을 통해서 데이터를 보내면 네트워크 모델에 따라 목적지 호스트에 데이터가 도착하게 되고, 데이터를 담은 봉투에 써진 도착지의 포트 넘버와 같은 포트를 할당받은 프로세스를 찾아서, 그 프로세스의 소켓을 통해 해당 프로세스에 데이터를 전달한다.
(포트: 프로세스를 식별하기 위해 프로세스가 할당받는 고유한 값. 호스트에는 여러 프로세스가 동시에 작동하는데, 데이터를 보내는데 어느 프로세스로 보내는지 안알려주면 안됨;; 그니까 포트 넘버를 지정해준다.
소켓은 그냥 데이터 보내려면 꼭 열어야하는 친구임. 한 소켓에는 포트 넘버, 아이피주소(호스트 주소, 32bit), 프로토콜(TCP/UDP) 지정해줘야함. 한 프로세스에 여러 소켓 열어서 여러개 데이터 보낼 수 있다(당연). 그냥 소켓은 데이터 보낼 때 필수적으로 여는 거임)
3. 트랜스포트 서비스 선택
트랜스포트 프로토콜은 여러 종류가 있고, 제공하는 서비스 다름. 개발하고자 하는 서비스의 성격을바탕으로 프로토콜을 선택하면 됨!
-> 프로토콜이제공하는 서비스
1. data integrity
-신뢰적 데이터 전송 ! 얼마나 손실이 없도록 보장을 할 것인지
-email 같은 전송 및 재무 애플리케이션들은 데이터 손실 없도록
-오디오, 비디오 같은 멀티미디어 애플리케이션에는 손실허용! 조금은 ㄱㅊㄱㅊ
2. throughput
- 어느정도의 처리량을 보장하는가
- 완전 필요할수도 잇고 많으면 많은대로 적으면 적은대로 이용할 수도 있다(탄력적. elastic)
3. timing (시간)
- 시간 보장!
- 키보드/뭐 실시간 애플리케이션(화상회의) 는 시간의 낮은 지연이 필요함. 실시간 !!
4. security
- 보안서비스. 암호화
인터넷 전송 프로토콜이 제공하는 서비스
( 인터넷 애플리케이션 개발시, UDP/TCP는 꼭 선택해야함~)
1. TCP - guarantee
- 연결 지향형 서비스 ; 어플리케이션 계층에 메세지 전송 전에, TCP는 클라이언트와 서버가 서로 전송 제어 정보를 교환하도록 함(핸드셰이킹. 곧 패킷 도달할거니 준비하라고 알려주는 거임. 이후 TCP연결이 두 프로세스의 소켓 사이에 존재한다고 얘기함, 전이중연결임. 전송마치면 연결끊음)
- 신뢰적 데이터 전송 ; 모든 데이터 오류없이 올바른 순서로 전달. 손실x도록!
- 혼잡제어방식 포함.(네트워크가 혼잡상태->프로세스 속도 낮춤)
https://sleepyeyes.tistory.com/4
2. UDP - 개런티 x
- 최소의 서비스 모델을 가진 간단한 프로토콜.
-비연결형(->핸드셰이킹x)
-비신뢰적 데이터 전송 ; UDP소켓으로 보내도 수신 소켓에 도착하는걸 보장 x. 순서가 바뀔수도 ㅇ
-혼잡제어방식x -> 데이터 원하는 속도로 보낼 수 ㅇ! (빠름)
ex) 스카이프같은 인터넷 저나. -> 패킷 손실 허용하지만 효율성을 위해 최소의 전송속도가 필요! 그래서 UDP선택. (TCP의 혼잡 제어 방식과 패킷 오버헤드를 회피함)
2.2 Web and HTTP
* 개요
- 웹페이지는 객체object들로 구성됨, 대부분 웹페이지는 기본 html파일과 여러 참조 객체로 구성됨
- object = 단순히 단일 url로 지정할 수 있는 하나의 파일 (jpeg/html/gif ..)
- 웹브라우저 = http의 클라이언트 측.
- 웹 서버=http의 서버측
-HTTP는 웹 클라이언트가 웹 서버에게 웹 페이지를 어떻게 요청하는지와, 서버가 클라이언트로 어떻게 웹 페이지를 전송하는지를 정의함
- 주고받는 메세지 = response, request
- HTTP는 TCP를 전송 프로토콜로 사용
- HTTP는 비상태 프로토콜 stateless protocol (서버가 클라이언트에게 요청 파일 보낼 때, 서버는 클라이언트에 대한 어떤 상태 정보도 저장 xx)
1. http connection
a. non-persistent connection (비지속 연결)
: 각 요구, 응답 쌍이 분리된 TCP연결을 통해 보내진다
-서버가 객체를 보낸 후에 TCP연결이 끊어짐! 각 TCP연결은 하나의 요청,응답 메세지만 전송하는 것
(응답,요청 할 때마다 TCP연결이 바뀜)
ex) www.어쩌구/경로 (html파일+10개 jpeg파일)
1. HTTP클라이언트는 http의 기본 포트번호 80을 통해 www.어쩌구 서버로 TCP연결 시도 (연결 초기화)
(당연히 클라이언트, 서버에 각각 소켓이 있게됨. 소켓할당(소켓=문))
2. HTTP클라이언트는 위에서 설정된 TCP연결 소켓을 통해 서버로 HTTP요청 메세지를 보냄. 이 요청 메세지는 경로 포함하게됨(그걸 요구하는거니깐)
3. HTTP서버는 위에서 설정된 TCP연결 소켓을 통해 요청 메세지를받고, 해당 경로 객체를 추출. 그리고 응답 메세지에 해당 메세지를 캡슐화함. 그리고 소켓을 통해 보냄
4. HTTP서버는 TCP에게 TCP연결을 끊으라고 함(그러나 실제로는 TCP클라이언트가 응답 메세지 올바로 받을 때까지 연결 끊지 x)
5. 클라이언트가 메세지 받으면 TCP연결 중단됨, 메세지로부터 html파일 조사하고, 10개의 jpeg객체에 대한 참조를 찾음
6. 참조되는 각 제이피쥐 객체에 대해 처음 네단계 반복하게됨
->11개의 TCP연결 만들어짐
-RTT: 패킷이 클라이언트로부터 서버까지 가고, 다시 클라이언트로 되돌아오는 데 걸리는 시간(클->서->클)
이건 패킷 전파 지연, 중간 라우터 등등 지연을 모두 포함함
- HTML요청, 수신까지 걸리는 시간?
= 2RTT + file transmission time

-단점s
- 각 요청 객체애 대한 새로운연결이 설정되고 유지되어야함!! TCP버퍼 할당 +TCP변수들이 클,서버 양쪽에 유지되어야함 ㅡㅡ 서버에게 심각한 부담 가능 (넘 많은 TCP연결!)
- 2RTT를 필요로함! (1-TCP연결 설정, 2-객체 요청하고 받기)
b. persistent connection (지속 연결)
: 모든 요구와 그에 해당하는 응답은 같은 TCP연결상으로 보내진다
-서버는 응답보낸 후에 TCP연결 그대로 유지함
- > 같은 클라이언트와 서버간의 이후 요청, 응답은 같은 위 연결을 통해 보내짐!!
-진행중인 요구에 대한 응답 기다리지 않고 연속해서 다른 객체에 대한 요구 가능. 서버도 객체를 연속해서 내보냄
(객체에 대한 요구는 진행중인 요구에 대한 응답 기다리지 않고 연속해서 만들어질 수 있다(파이프라이닝))
-서버가 연속된 요구 수신->서버는 개체 연속해서 보냄
-default임!!
2. http message format
a. http request message

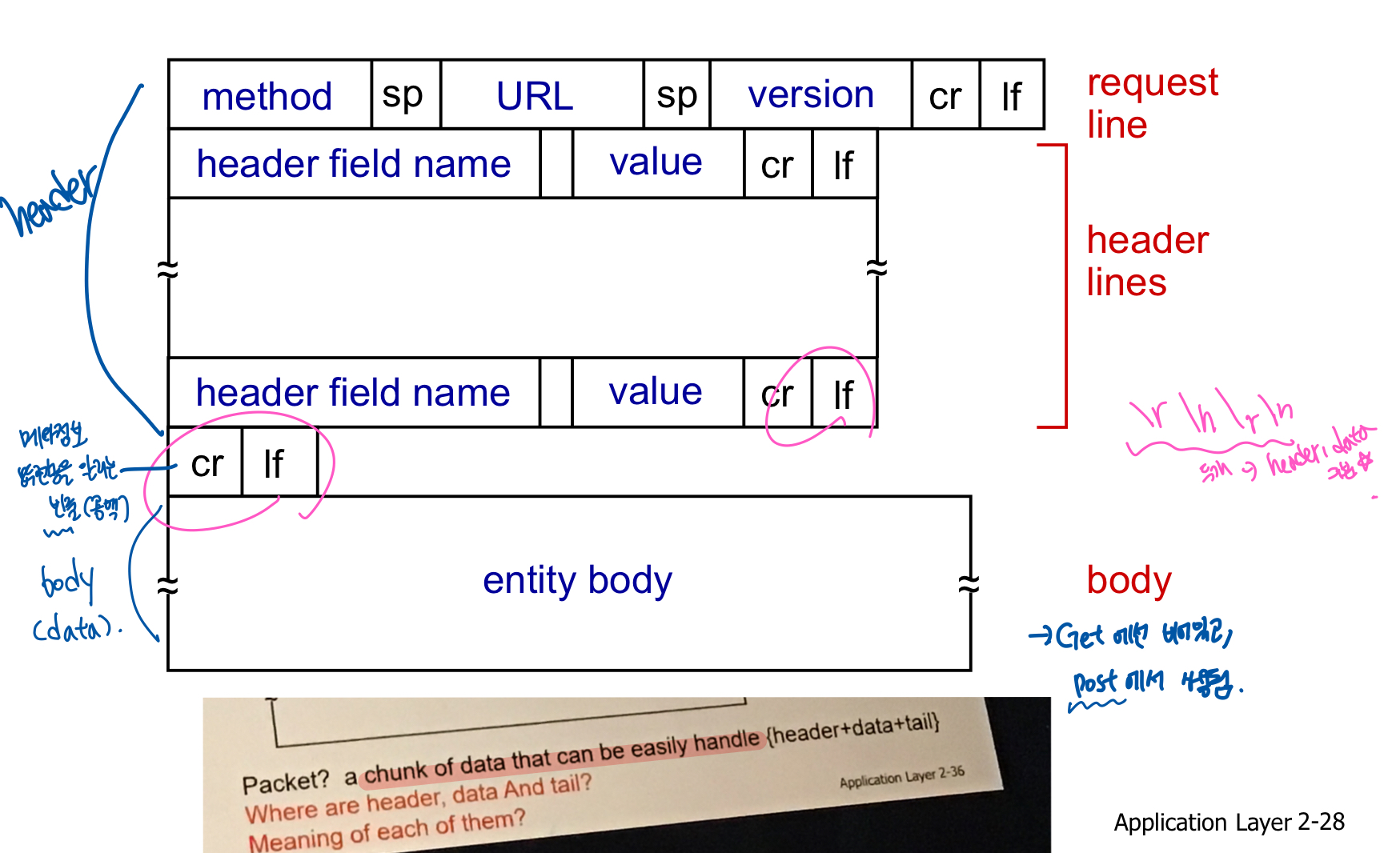
- HTTP 요청 메소드
= 클라이언트가 웹서버에게 요청하는 목적 및 그 종류를 알리는 수단, 요청 메세지의 젤 첫째줄에 있음
- POST: 서버에 뭐 보낼때. 인풋(웹페이지도가능)은 entity바디에 담기고, 서버에 전달됨 (ex. 검색엔진에 단어 넣을 때)
- GET: 리소스 취득. URL(URI) 형식으로 웹서버측 리소스(데이터)를 요청. 걍 URL객체 요청. 요청하고잇는애(input)은 URL field에 담김!!
- DELETE : 파일 삭제. 웹 리소스를 제거
- PUT: 내용 전송 (파일 전송도 가능) - 클라이언트에서 서버로 어떤 정보를 제출함 . 요청 데이터를 HTTP 바디에 담아 웹서버로 전송함
- HEAD : 메세지 헤더(문서 정보) 취득 - GET과 비슷하나, 실제 문서를 요청하는 것이 아니라, 문서 정보를 요청
b. http response message

- status code (첫줄에 적힘)
- 200 OK ( 요청이 성공되었고, 정보다 응답으로 보내졌다)
- 404 NOT FOUND (요청문서가 서버에 없다)
- 505 HTTP Version Not Supported (요청 HTTP프로토콜 버전을 서버가 지원하지 않는다)
- 400 Bad request (서버가 요청을 이해할수업듬 ㅗㅗ)
- 301 Moved Permanently
3. user-server state : cookies
(사용자와 서버간의 상호작용 - 쿠키 !!)
* http - stateless ! (상태유지 x. 사용자 정보 저장 x)
-> 사용자 확인하는게 필요할 때 ㅇ -> 쿠키 사용 ! -> 사이트가 사용자를 추적하도록 해준다
쿠키의 4가지 components (활용하는 것들)
- http응답 메세지의 쿠키 헤더라인 (맨첨)
- http 요청 메세지의 쿠키 헤더라인 (담 요청)
- 사용자의 브라우저에서 관리되고 사용자 host에 있는 쿠키파일 (?)
- 웹사이트의 벡엔드 데이터 베이스
: 사이트에 접속하면 서버가 사용자에 대한 유일한 식별 번호 unique id ! 를만들고, 그걸 백엔드 디비에 저장함. http응답메세지에 이 쿠키 정보 넣음.
그러면 브라우저가 관리하는 쿠키 파일에 그 라인을 덧붙이게 됨(서버호스트네임+쿠키)
나중에 또 이 사이트 접속시에 웹페이지 요청시 이 쿠키파일 참조하여 번호를 요청파일에 포함함. cookie:1678 이런식의 헤더라인 포함함
-> 웹사이트는 1678사용자가 어느페이지를 어떤 순서로 방문했는지 정보들 알 수 ㅇ (요청파일에 적혀있으므로)

- 문제점 : 사생활 침해 가능. 웹 사이트가 사용자에 대한 많은 것을 알 수 있기 때문에 이 정보를 어떻게 활용할지 모름. 제 3자에게 판매 가능 ...
- 활용 -> 쇼핑 카트, 추천시스템, 웹 이메일,,
4. web cache (proxy server)

- 목적: 서버없이 client request 처리하기. client request 에 response time 줄이기
- 웹캐시는 자체의 저장 대스크를 갖고 있어 최근 호출된 객체의 사본을 저장, 보존 한다
-> 브라우저는 사용자의 모든 HTTP 요구를 웹 캐시에 가장 먼저 보냄!
-과정
- 브라우저는 HTTP 요청을 웹캐시에 보냄
- 웹 캐시는 객체의 사본이 자기에게 있는 지 확인. 있으면 해당 객체를 HTTP 응답 메세지와 함께 전송
- 없으면 원 서버로 TCP연결 하고 요청 보냄. 객체를 HTTP응답 메세지와 웹캐시로 보냄
- 웹 캐시가 객체를 수신할 때 ,객체를 지역 저장장치에 복사하고 클라이언트 브라우저에 객체의 사본을 HTTP응답 메세지와 보냄
- 일반적으로 웹 캐시는 ISP가 구입하고 설치함
- 캐시는 서버이면서 클라이언트~~ (브라우저로부터 요구받고 응답보내는 것 = 서버 / 출처 서버에게 요구보내고 응답받는 것=클라이언트)
- 장점
- 클라이언트의 요구에 대한 응답시간 줄일 수 ㅇ (클-캐가 연결 더 높은속도임 그래서 캐시에 잇으면 훨씬 이득임)
- 한 기관에서 인터넷으로 접속하는 링크상의 웹 트래픽을 줄여줌
-조건부 get (conditional get)
* 캐시 내부에 있는 복사본이 새것이 아닐수도 있음 !!! (웹서버에 있는 객체가 갱신되었을 수 있다)
-> 모든 객체들이 최신의 것임을 확인하면서 캐싱하는 것 = 조건부 get !
-> 캐시에있는 복사본을 사용할지, 서버로부터 가져올지를 결정하는 것이 바로 이 조건부 get
- 서버로부터 캐시에 객체를 저장할 때, 해당 객체가 마지막으로 수정된 날짜도 같이 저장한다
- 브라우저가 캐시에게 객체 요청하게 되면 -> 조건부 get 조사 수행 (아마도)
조건부검사; 서버에게 if-modified-since: 마지막수정날짜 이 정보 포함해서 보내고,
1. 만약 수정되었을 경우-> 200 OK 하고 데이터 보냄
2. 수정 안되었으면 -> 304 Not Modified 하고 데이터 안보냄 !! (entity body 비어있음) (캐시의 복사본 사용해라)
2.4 DNS
* host는 ip 주소로 식별한다 (ip=4바이트, 10진수, 계층구조)
0. dns
= 호스트 name을 ip주소로 변환해주는 디렉터리 서비스!
-> 다른 애플리케이션 프로토콜(HTTP, SMTP, FTP)들이 사용자가 제공한 호스트네임을 ip주소로 변환하기 위해 사용!
- application layer protocol임
- UDP상에서 수행, 포트번호 53
- 분산 데이터베이스임
- 호스트가 분산 데이터베이스로 질의하도록 허락하는 애플리케이션 계층 프로토콜 (유저가 ip주소잇는 디비에 접근하게 해주는 프로토콜)
ex. 사용자의 브라우저가 URL을 요청하면? -> ip주소얻어야댄다 ! -> dns!
1. 사용자 컴은 DNS애플리케이션의 클라이언트쪽을 수행
2. 브라우저는 호스트네임을 추출하고, 이걸 dns클라이언트측에 넘김
3. dns클라이언트는 dns서버로 호스트네임을 포함하는 질의를 보냄
4. dns클은 응답받게됨 ip주소얻음
5. 브라우저는 그 ip주소와 그 주소의 80번 포트에 위치하는 http서버 프로세스로 tcp연결을 초기화한다
-dns의 서비스
- hostname to ip address
- host aliasing : 별칭네임에 대한 정식 호스트네임을 얻게 해줌 (정식호스트네임 = canonical hostname) (복잡한 호스트네임 가진 호스트는 하나이상의 별명 가질 수 있음. 하나이상의 호스트네임!!)
- mail server aliasing : 메일의 별칭호스트네임에 대한 정식 호스트네임을 얻게 해줌 (hanmail.com으로 쓰지만 실제 핫메일 서버의 호스트네임은 더 복잡함!!)
- load distribution : 여러 중복 서버 사이에 부하를 분산하기 위해 사용 (인기잇는 사이트들은 이용자 넘 마느니까, 중복 웹서버 를한다 ! 모냐면 한 호스트네임에 여러 ip주소가 할당되어 각 서버가 서로 다른 종단 시스템에서 수행되고, 다른 ip주소를 갖도록 하는 것이다. dns는 한 호스트네임에 대해 ip주소 여러개를 가지고 있고, 각 응답에서 주소는 순환식으로 보낸다)
1. 동작 원리 개요 - hostname->ip
*dns처리과정 = preprocessing ( 데이터를 다루기쉬운 형태로 변환시킨다 )
dns측의 클라이언트를 호출, 질의메세지보냄(포트 53의 udp 데이터그램으로 보내짐)-> 요청한 매핑에해당하는 dns응답 메세지 받음->애플리케이션으로 전달
-이러한 서비스를 제공하는 건 사실 복잡. 전세계에 분산된 많은 dns서버 + dns서버와 질의를 하는 호스트사이에서 어떻게 통신하는지를 명시하는 애플리케이션 계층 프로토콜로 구성되어잇음
-간단 설계: 모든 매핑을 포함하는 하나의 인터넷 네임 서버 ! (중앙 집중 방식)
-> 클라이언트는 모든 질의를 단일 네임 서버로 보내고, 이 서버는 클에게 직접 응답함!
-> 적합x. 이유는
- 서버의 고장 : 서버 고장나면 전체인터넷작동안함
- 트래픽 양 : 단일 dns서버가 모든 dns질의를 처리해야함! 수많은 요청 처리,,
- 먼 거리의 중앙 집중 db : 멀어서 지연일으킬수 ㅇ (호주->미국,,)
- 유지 관리 : 이 서버는 모든 인터넷 호스트에 대한 레코드를 유지해야함! 당연히 자주 갱신해야함 어려움 유지관리어려움
-> 결론은, 확장성이 전혀 없다 ! -> 분산되도록 설계됨
분산 계층 데이터 베이스
: 확장성 문제를 다루기 위해 DNS는 많은 서버를 이용하고, 이들을 계층 형태로 구성하여 전세계에 분산시킴
- 로컬 dns 서버 : 계층구조에 엄격하게 속하지x. dns구조의 중심에잇음. 대체로 호스트에 가까이 있음. 프록시처럼 동작함
- 루트 dns 서버 : 로컬이접근하게 됨
- TLD(최상위 도메인) 서버 : com, org, net같은 상위레벨 도메인에 대한 서버이다.
- authoritativee DNS 서버 (책임) : 해당 기관의 이 책임 DNS서버에는 DNS레코드가 있따. DNS레코드=ip와 호스트네임 매핑하는 것. 여기서 결국 ipdjerpehla
과정 - query and response !
- requesting 호스트가 local에 query (질의) 함 (변환해야하는 호스트네임 포함)
- cache된게 없으면 해당 쿼리를 루트 서버에 전달
- .com을 인식하고 com에 책임을 가진 TLD서버의 ip를 로컬에게 줌
- 로컬은 해당 TLD서버에 쿼리 보냄
- 해당 호스트네임(주소)로 이름지어진 책임서버의 ip로 응답함
- 로컬은 해당 책임서버로가서
- ip주소를 받고
- 요청호스트에게 전달
-재귀적 질의 recursive query : 자신 대신에 필요한 맵핑을 얻도록 하는거. 위 계층에게 짐을 부여하는것
- 반복적 질의 iterated query : 질의된 도메인에 대해 응답하거나, 로컬 dns서버가 다른 서버에게 쿼리를 보내 답을 요청하는 작업. (답알고있는 다른 친구에게 물어보는거) -> 클라이언트는 다수의 dns서버들에게 같은 질의를 반복할 수 있다
caching
호스트 네임과 ip주소쌍이 dns로컬서버에 저장된다 영구적은 아니고 대충 2일정도의 기간동안 전달된다
다른호스트로부터 해당 질의가 또오면 그냥 루트갈피료없이 그냥 잇는거 보내주면 된다ㅏ 다른 dns서버로의 질의가 필요없다 !!
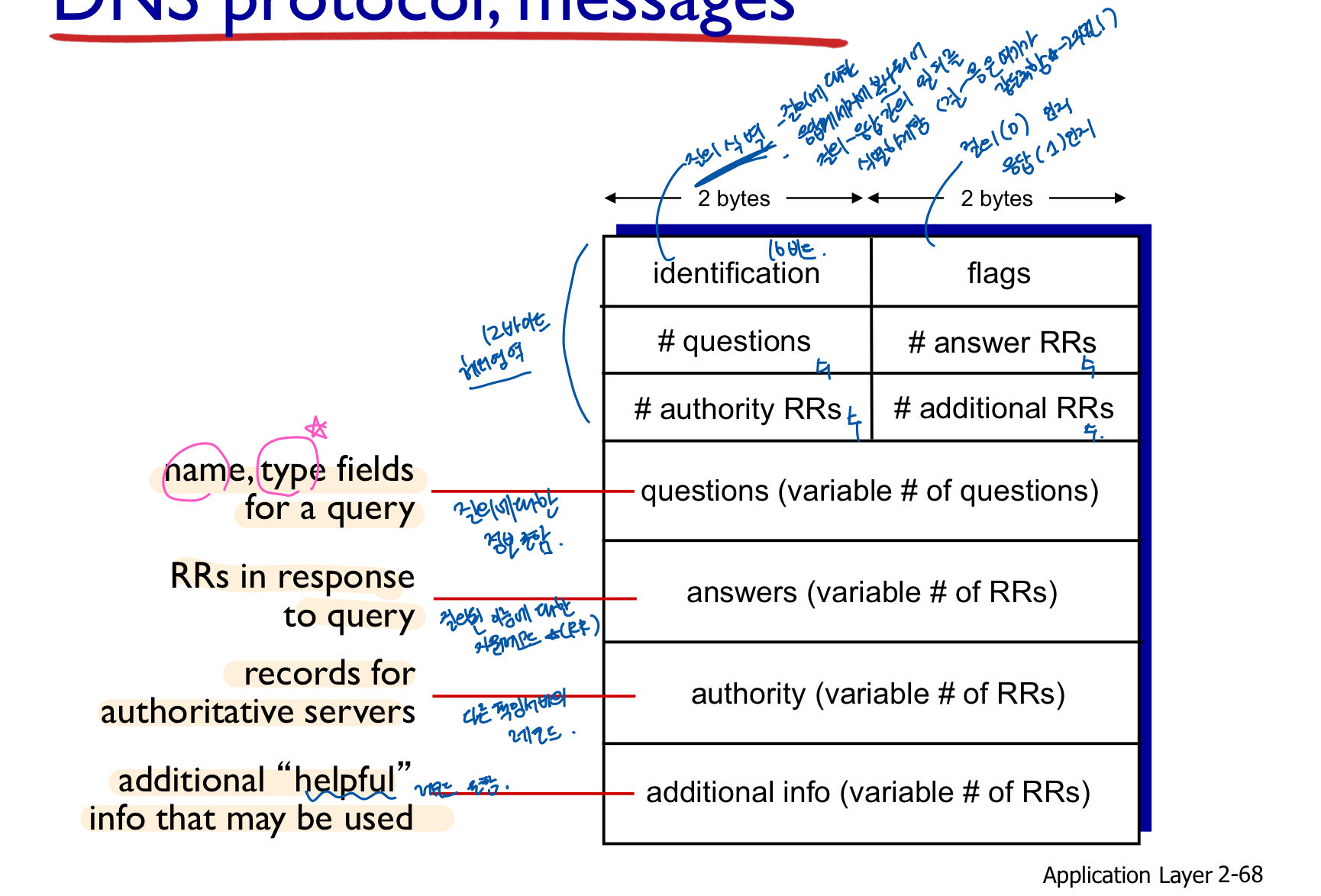
2. dns records and messages
resorce record=RR format
(name, value, type, ttl) (ttl=캐시할때제거되는 시간)
- type 종류
- A : name-hostname, value-ip address
- NS : name-도메인(foot.com같은거), value-책임dns서버의 호스트네임
- CNAME : name-별칭호스트네임 alias name, valie-canonical name (정식 이름)
- MX : name-별칭호스트네임 alias name (메일 서버), valie-메일 서버의 정식 이름
dns message
-> query와 reply는 같은 message format을 가지고 있다
inserting records into DNS (database)
'2-2 > 컴퓨터 네트워크' 카테고리의 다른 글
| Chap 1. 컴퓨터 네트워크와 인터넷 (0) | 2021.10.05 |
|---|