lower bounds for sorting - comparison sorts
comparison sorts
=비교만 사용하여 정렬하는 알고리즘 (heap sort, mergesort, insertion sort, selection sort, quick sort)
-> worst case의 lowerbound는 (worst의 최소. 무조건이거보다는더안좋다) : Ω(nlgn)
decision-tree model
- comparisoin sort은 이 디시션 트리의 관점으로 볼 수 있따 ! (이게 기본개념)
- 모든 친구들이 distinct라고 가정함 -> <=연산만 하면 된다! 이게 성립하면 <=이고 아니면 > 에 들어가면 댐
~tree 개념~
- full binary tree임
- leaf는 input elements의 순열이다 (정렬한거)
- 각 internal node i:j는 i번째, j번째 element의 크기를비교하는 것이다 (ai<=aj?) (i,j는 인덱스 !!)

- 실행 횟수 = 리프까지의 높이가 됨 ! (degree인가? 멀라)
( <=연산 하나밖에 업스니까)
-> worst-case number of comparison = height ! (height=루트 빼고 개수임. 루트의 자식개수라서)
-> comparision sort algorithm은 Ω(nlgn) 비교를 worst case 에서 요구한다 !
증명하기
* O(nlgn)보다 줄일 수 있는 방법은 Comparison을 하지 않는 것. -> 이거보다 더 작은 worst running time가진 두가지 방법 소개
counting sort
= comparision말고 counting을 사용하는 sort algorithm !!
-> 리스트에 들어있는 각 요소의 개수를 새서 새 리스트에 적고 그걸 토대로 sort를 한다 !
* stability
= sort했을 때 같은 값들은 순서가 지켜져야 한다 ! additional data의 순서가 유지될 수 있도록 ! 그래야 stable하다고 말함.
sort alg는 꼭 이거 지켜야됨!
알고리즘 순서
1. 개수 새는 counting list를 만든다
2. 앞친구와 더해서 해당 숫자의 마지막 index를 가리키는 list를 또 만든다
3. 그걸 토대로 새 어레이를 만든다
(이 만드는 counting list는 최소숫자 ~ 최대 숫자가 다 있다. 0~5까지면, 인풋리스트에 다 없더라도 012345가 counting list대상 숫자가 된다)
새어레이 (output sorted list)만들기
1. 원래 list의 맨 마지막요소부터 첨까지 차례로 하나씩 가는거임! 이거반복임
2. 만든 list에서 해당 마지막 요소에 해당하는 값(index)를 구하고, 결과 리스트 해당 인덱스에 해당 숫자 넣음
3. 만든 리스트에서 해당 숫자에 해당하는 값 -1을 함
4. 그리고 다시 이과정 반복함! input리스트에 하나 전 숫자를 대상으로.
슈도코드
A=input array, B=output array, k=range of numbers(최대 숫자)

running time
: Θ(k+n). (k= range of input integers)
1. k=O(n)이면 러닝타임은 Θ(n)이 됨
2. 아니면,, k=10^8 이딴 숫자면 좃댐. 러닝타임은 Θ(k)이 됨
-> k가 small일 때만 이 방법은 효율적이다 !
Radix sort
radix : 주어진 데이터를 구성하는 기본 요소의 개수를 의미한다. 따라서 2진수는 0과1, 10진수는 0~9, 영문자는 a~z까지 각 2,10,26가 기수가 된다.
-> 데이터를 구성하는 기본 요소 (Radix) 를 이용하여 정렬을 진행한다 !
종류
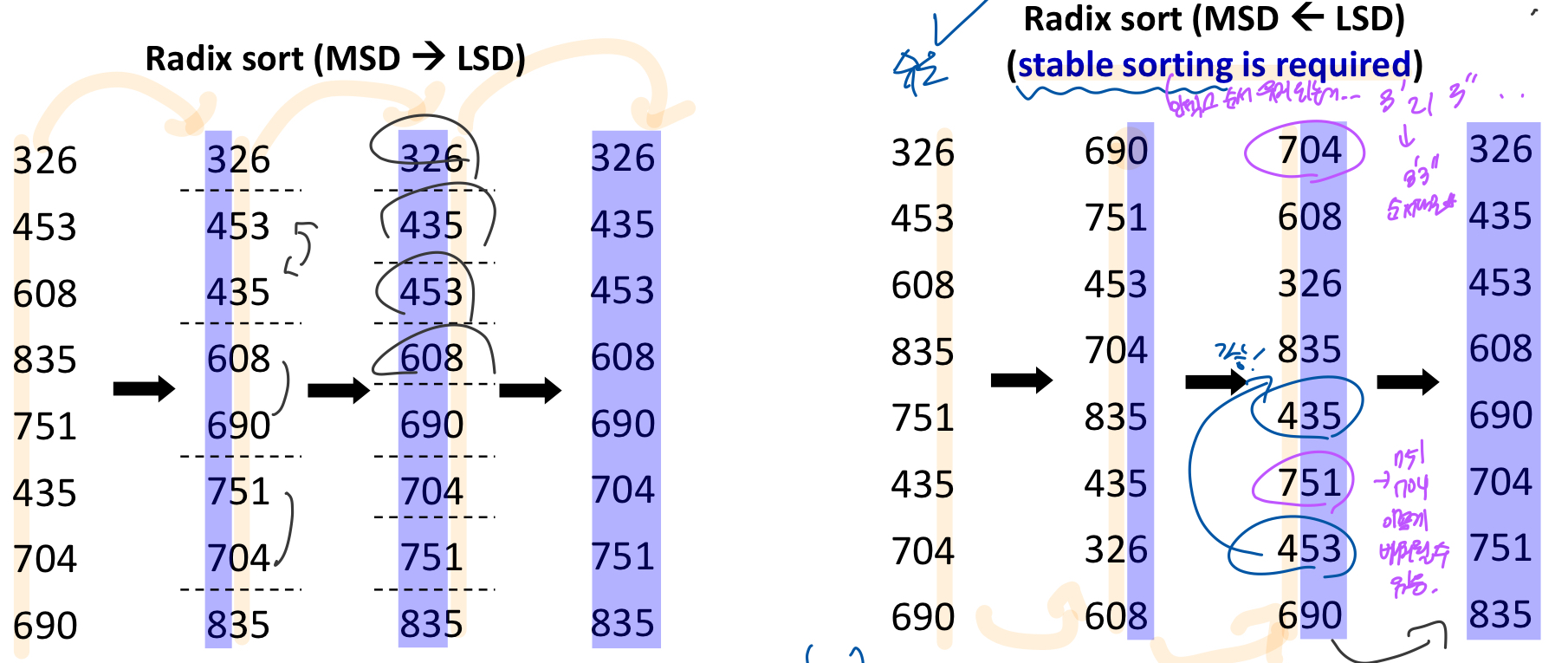
1. MSD -> LSD : 높은자리수부터 쭉 비교하는거 (각 그룹내에서 비교하게 된다)
2. MSD <- LSD : 낮은 자리수부터 쭉 비교하는거 - 전체를 기준으로 그냥 정렬함 (group x)
-> stable sorting이 요구됨 !!
-> 1은 알고리즘이 일관적이지 않은 반면 얘는 일관적인 알고리즘이 있어서, 일반적으로 radix sort하면 이걸 말하게 됨
'구현의 편의성'으로 일반적인 기수 정렬(radix sort)은 LSD 방식을 기준으로 한다(성능차이x).
-> 나도 슈도코드 이런거 얘를 기준으로 합니다
슈도코드
* d= 자릿수. 즉 정렬 해야하는 횟수 !
-> 각 자릿수별로 counting sort를 한다 ! k=10이라서 복잡도 ㄴㄴ 완전 굳 대안임
RADIX-SORT (A,d)
for i = 1 to d
use a stable sort to sort array A on digit i - counting sort 함 !! ( = Θ(k+n) )
-> 연산횟수 : Θ(d(k+n)) 인데, 이때 d는 상수로 정해져 있고, k는(설정이기나름이지만) O(n)이므로 이 알고리즘은 linear time을 가짐 ! Θ(n)인듯
d, k
-> 얘네는 우리가 radix를 뭘로 설정하느냐에 달렸다 !
ex)

->어떻게 running time을 minimize하는 radix를 선택할 수 있는가 ?
'2-2 > 알고리즘' 카테고리의 다른 글
| dynamic programming (0) | 2021.10.17 |
|---|---|
| quick sort (0) | 2021.10.15 |
| Heapsort (0) | 2021.10.12 |
| Solving recurrences (0) | 2021.10.10 |
| Asymptotic notation (0) | 2021.10.10 |